その日の学びをその日にまとめたい
仕事しているとき、家で勉強しているとき、散歩しているとき、いろいろ頭の中で考えることがあります。しかしぐるぐるとした思考はどんどんと流れていってしまいます。わからないことは検索して”答え”ないしは”最適解”、最適解を探します。その時見つけたものをなんとなくメモしているのですが、外向けに公開できるほどまとめきれず正確に把握しきれないままいろいろなこと追われてしまいます。
時間はないですができる限りその日に得た知見をその日のまま、まとめていけれたらいいなと思います。
Webアプリのひな型みたいなのを作った[DockerCompose+React/TS/Vite+Python/FastAPI+MySQL]
前置き
最近はR&Dで働く葛です。お久しぶりです。
小さなWebアプリを小さく初めて、試作品をたくさん作りたいと思っているのにあんまりフレームワークがないなと思っていました。
なんでもいいのでFrontend, Backend, Databaseをフルカスタマイズ可能で小さくサクッと始めるために今回作ってみました。
やったこと
- Frontend + Backend + Database のコンテナを立ててるDockerComposeを造りました。
- Frontendは Vite + React + TypeScriptです。(これは viteでプロジェクト建てただけ)
- Backendは Pythonの FastAPIです。
- Databaseは MySQLです。
環境
Windows11+WSL+Ubuntu 22.03です。
ディレクトリ構成
$ tree -L 2
.
├── backend
│ ├── Dockerfile
│ ├── README.md
│ ├── __pycache__
│ ├── config
│ ├── database
│ ├── main.py
│ ├── models
│ ├── requirements.txt
│ ├── routers
│ └── services
├── docker-compose.yml
├── docs
└── frontend
├── Dockerfile
├── README.md
├── index.html
├── node_modules
├── package-lock.json
├── package.json
├── public
├── src
├── tsconfig.json
├── tsconfig.node.json
└── vite.config.ts
docker-compose.yml
以下はとりあえずローカルで適当に動かすためだけに作りました。SQLのパスワードなどを直書きしているので、実運用させたい場合は、環境変数化したりして適宜変更が必要だと思います。
services:
backend:
build: ./backend
ports:
- "8000:8000"
depends_on:
- db
volumes:
- ./backend:/app
db:
image: mysql:8.0
command: --default-authentication-plugin=mysql_native_password
restart: always
environment:
MYSQL_ROOT_PASSWORD: sample_password
MYSQL_USER: sample_user
MYSQL_PASSWORD: sample_user_password
frontend:
build: ./frontend
ports:
- "5173:5173"
volumes:
- ./frontend:/app
説明
- frontendは port 5173でlistenさせています。
- backendは port 8000でlistenさせています。
- databaseはport 3306で自動的にlistenされていました。
- それぞれマウントさせて、Dockerコンテナ内での開発内容をローカルに反映させています。
Dockerfile
Frontend
# Use an official Node.js image FROM node:20 # Set the working directory in the container to /app WORKDIR /app # Add the current directory contents into the container at /app ADD . /app # Install any needed packages specified in package.json RUN npm install # Run npm start when the container launche # CMD ["npm", "run", "dev"] # 開発時に起動させるためだけのコマンド CMD [ "tail", "-f", "/dev/null" ]
説明
- 最初にプロジェクトだけをviteで作るために、VSCodeの機能でdev containerを立てました。そのなかで viteを使ってプロジェクトを立ち上げました。
- プロジェクトのソースコードだけを作るのはcontainer内でやる必要がなかったかも。
- プロジェクトの作ったら、とりあえずコンテナを閉じました。
- CMDで npm run devをしてしまうと、開発中にコンテナを閉じたり建てたりを繰り返す必要が出てきます。これは非常に手間です。
- そこで 最後の行を追加して、何もしない tail コマンドを実行させて待機させます。その間に vscodeの
attach containerを使って起動中のコンテナに入ることで開発ができます。これが便利でした。
- そこで 最後の行を追加して、何もしない tail コマンドを実行させて待機させます。その間に vscodeの
Backend
FROM python:3.11 WORKDIR /app COPY . /app/ RUN pip install --no-cache-dir -r requirements.txt # CMD [ "uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000", "--reload" ] CMD [ "tail", "-f", "/dev/null" ]
ほぼやっていることは一緒です。
あれ、COPY っているんだっけ?(また調べます)
DatabaseとBackendの連携について
おそらくここが鬼門だったと思います。
最初にフレームワークの説明をします。
├── backend │ ├── config : 固定値などを入れる │ ├── database : SQL Alchemey │ ├── main.py : エントリーポイント │ ├── models : PyDantic │ ├── requirements.txt │ ├── routers : エンドポイント │ └── services : 業務ロジック
- SQL ALchemyを利用してDatabaseを定義します。またSQLを操作します。
- FastAPIでのデータのやりとりはPyDanticを利用します。
- データの連結イメージは以下です
- Database <-[SQL Alchemy]-> FastAPI <-[PyDantic]-> Frontend
main.py
# main.py from fastapi import FastAPI from routers.index_router import index_router from routers.user_router import user_router from models.base import Base from database.database import engine app = FastAPI() @app.on_event("startup") async def startup_event(): Base.metadata.create_all(engine) app.include_router(index_router) app.include_router(user_router)
FASTAPI のエントリーポイントは上のように書きました。最初にFastAPIを初期化します。
database.py
# database.py from sqlalchemy import create_engine, text from sqlalchemy.orm import sessionmaker DATABASE_URL = "mysql://root:sample_password@db:3306" # Link Docker Compose ENVIROMENT VARIABLE DATABASE_NAME = "new_database" # DB名を指定せずに接続する engine = create_engine(f"{DATABASE_URL}") # DBがなければ作成する with engine.connect() as connection: connection.execute(text(f"CREATE DATABASE IF NOT EXISTS {DATABASE_NAME}")) # 切断する engine.dispose() # 新しく作成したDBに再接続する engine = create_engine(f"{DATABASE_URL}/{DATABASE_NAME}") # SessionLocalクラスを作成 SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
database.pyではDBの初期化やセッション、接続などの基本部分を書きました。
DATABASEとの接続する際はDocker Networkを使うのでそこに合わせて使います。
base.py
from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
スキーマ定義のベース定義です。これを継承して各スキーマを定義していきます。
database.user_schema.py
from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base from models.base import Base class User(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(50)) email = Column(String(50))
Userというテーブルを作ります。
models.user_model.py
from pydantic import BaseModel class UserBase(BaseModel): name: str email: str class UserCreate(UserBase): name: str email: str class UserRead(UserBase): id: int name: str email: str class UserUpdate(UserBase): id: int name: str email: str
UserクラスにそれぞれCRUDに対応したクラスを定義しました。
これを使ってEndpointを定義していきます。
routers.user_router.py
# user_router.py from fastapi import APIRouter, Depends from sqlalchemy.orm import Session from models.user_model import UserCreate, UserRead, UserUpdate from database.database import SessionLocal from database.user_schema import User as UserSchema user_router = APIRouter() # 依存関係 def get_db(): db = SessionLocal() try: yield db finally: db.close() @user_router.post("/users/", response_model=UserCreate) def create_user(request_user: UserCreate, db: Session = Depends(get_db)): user_schema = UserSchema() user_schema.name = request_user.name user_schema.email = request_user.email db.add(user_schema) db.commit() db.refresh(user_schema) return user_schema @user_router.get("/users/{user_id}", response_model=UserRead) def read_user(user_id: int, db: Session = Depends(get_db)): user = db.query(UserSchema).filter(UserSchema.id == user_id).first() return user @user_router.put("/users/{user_id}") def update_user(user_id: int, user: UserUpdate, db: Session = Depends(get_db)): db_user = db.query(UserSchema).filter(UserSchema.id == user_id).first() db_user.name = user.name db_user.email = user.email db.commit() db.refresh(db_user) return db_user @user_router.delete("/users/{user_id}") def delete_user(user_id: int, db: Session = Depends(get_db)): user = db.query(UserSchema).filter(UserSchema.id == user_id).first() db.delete(user) db.commit() return {"message": "User deleted successfully"}
CRUDのエンドポイントを作ってみました。 それぞれ PyDanticで受け取ったデータをORMでSQL Alchemryに変換してDBとやりとりします。
以上で実装は終わりです。
CURLで動作確認してみる。
- ユーザーの作成(POST /users/):
curl -X POST "http://localhost:8000/users/" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"name\":\"string\",\"email\":\"user@example.com\"}"
- ユーザーの読み取り(GET /users/{user_id}):
curl -X GET "http://localhost:8000/users/1" -H "accept: application/json"
- ユーザーの更新(PUT /users/{user_id}):
curl -X PUT "http://localhost:8000/users/1" -H "accept: application/json" -H "Content-Type: application/json" -d "{\"id\":1,\"name\":\"new_name\",\"email\":\"new_email@example.com\"}"
- ユーザーの削除(DELETE /users/{user_id}):
curl -X DELETE "http://localhost:8000/users/1" -H "accept: application/json"
DockerのSQLに入って確認してみる
MySQL Docker
docker compose run db mysql -h db -u root -psample_password
上は本来非推奨 パスワード直打ちだからです。
-h db オプションを追加したことで、MySQLクライアントはDocker Network経由でMySQLサーバーに接続しようとしました。これは、Docker環境では各コンテナが独自のネットワーク空間を持っているため、localhostや127.0.0.1ではなく、サービス名(この場合はdb)を使用して他のコンテナに接続する必要があるからです。
あとは作成したDBを適宜確認すればOKです。
最後に
今回は上のようなものを作ってみました。
BACKENDとDBの骨子ができれば、あとはFrontendにUIを作って、JSONを描画させて、BACKENDに業務ロジックを実装するだけですね。
おそらくはもっと考慮すべき事項もあると思いますが、今回はこれくらいにします。
何か気になった指摘があればください。
WSL2を任意のドライブにインストールする
WSL2を任意のドライブにインストールする
0. WSL2導入準備
command lineベースで行うので、以下を参考に導入を進めてください。
https://learn.microsoft.com/ja-jp/windows/wsl/install-manual
0-1. 手順 1 - Linux 用 Windows サブシステムを有効にする
管理者権限で開いたPowerShellで以下を実行する。
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
0-2. 手順 2 - WSL 2 の実行に関する要件を確認する
WSL 2 に更新するには、Windows 10 を実行している必要があります。
- x64 システムの場合: バージョン 1903 以降 (ビルド 18362.1049 以降)。
- ARM64 システムの場合: バージョン 2004 以降 (ビルド 19041 以降)。
- または Windows 11。
0-3. 手順 3: 仮想マシンの機能を有効にする
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
0-4. 手順 4 - Linux カーネル更新プログラム パッケージをダウンロードする
- 最新のパッケージをダウンロードします。
- これを起動してインストールします。
0-5. 手順 5 - WSL 2 を既定のバージョンとして設定する
wsl --set-default-version 2
MDSNの手順6は実行しません。
1. Ubuntu-22.04をインストールする
インストール可能なディストリビューションを確認します。
wsl --list --online
実行結果
> wsl --list --online インストールできる有効なディストリビューションの一覧を次に示します。 'wsl --install -d <Distro>' を使用してインストールします。 NAME FRIENDLY NAME Ubuntu Ubuntu Debian Debian GNU/Linux kali-linux Kali Linux Rolling Ubuntu-18.04 Ubuntu 18.04 LTS Ubuntu-20.04 Ubuntu 20.04 LTS Ubuntu-22.04 Ubuntu 22.04 LTS OracleLinux_7_9 Oracle Linux 7.9 OracleLinux_8_7 Oracle Linux 8.7 OracleLinux_9_1 Oracle Linux 9.1 openSUSE-Leap-15.5 openSUSE Leap 15.5 SUSE-Linux-Enterprise-Server-15-SP4 SUSE Linux Enterprise Server 15 SP4 SUSE-Linux-Enterprise-15-SP5 SUSE Linux Enterprise 15 SP5 openSUSE-Tumbleweed openSUSE Tumbleweed
実際にインストールを行います。
wsl --install -d Ubuntu-22.04
実行結果
wsl --install -d Ubuntu-22.04 インストール中: Ubuntu 22.04 LTS Ubuntu 22.04 LTS はインストールされました。 Ubuntu 22.04 LTS を起動しています...
自動的に別ウィンドウでターミナルが立ち上がります。
USERNAMEとPASSWORDを作成します。
3. WSLをエクスポートする
powershellで実行します。このとき移行先に出力しておきます。今回はG Driveにしました。
wsl --export Ubuntu-22.04 G:\Ubuntu.tar
4. 作成したWSL2インスタンスを削除します
wsl --unregister Ubuntu-22.04
5. エクスポート先からWSL2をインポートする
wsl --import Ubuntu-22.04 G:\wsl G:\Ubuntu.tar
7. WSL起動時のデフォルトユーザー変更
このまま起動すると root userで入ってしまうので、これを対応します。
vi /etc/wsl.conf で下記内容をファイルの末尾に直接書き込みました.
[boot] systemd=true [user] default=YOUR_USERNAME
一度ターミナルを閉じてください。この時何度かログインやログアウトターミナルを閉じたりをすることで、設定が反映されました。
改めてwslを開くとUSERNAMEでログインできていると思います。
参考文献
【GitLab】Ubuntu + Vagrant でGitLabをローカルに構築する
この記事でわかること
自分の環境
概要
今回の手順は以下です。
- brewのインストール
- VirtualBoxのインストール
- Vagrantのインストール
- Vagrantfileの作成
- VagrantでUbuntu22.04の仮想マシン立ち上げ
- UbuntuにSSHで入る
- GitLabのインストール
- localhostに接続
以上です。
Windows PCでも Vagrant 環境が用意できれば問題ないです。 HyperVやVMwareも対応しているらしいので各自調べてください。
brewのインストール
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- macOS(またはLinux)用パッケージマネージャー — Homebrew
- パッケージはbrew経由で用意したので各位それぞれの方法で導入してください
VirtualBoxのインストール
brew install --cask virtualbox
- virtualbox — Homebrew Formulae
- 公式サイトからインストールしても良いと思います
Vagrantのインストール
brew install --cask vagrant
Vagrantfileの作成
vagrant initで現在いる階層にVagrantfileが作成されるので新しくディレクトリを作っておきます。
mkdir ubuntu2204 && cd ubuntu2204 vagrant init bento/ubuntu-22.04
https://app.vagrantup.com/bento/boxes/ubuntu-22.04
disksizeプラグインを追加
次の作業で必要になるので以下のコマンドで追加します。
vagrant plugin install vagrant-disksize
Vagrantfileの編集
- デフォルトだと容量とメモリが少ないので、割り当てを追加します。
- またlocalhost:80を開けるためにポートフォアワードの設定をします。
- GitLabはデフォルトで8080で待つのでそれに合わせます。
- ファイルを開き以下のコードを差分を確認しながら追加してください
- # config.vm.network "forwarded_port", guest: 80, host: 8080 + config.vm.network "forwarded_port", guest: 80, host: 8080 + config.vm.provider "virtualbox" do |vb| + # Customize the amount of memory on the VM: + vb.memory = "4048" + config.disksize.size = '30GB' #容量を増やす時に追加する + end
vagrantの起動
vagrant up
UbuntuへSSH接続
vagramt ssh
GitLab Community Edition のインストール
- 公式Doc https://about.gitlab.com/install/#ubuntu
- ここを見ると Enterprise Edition についてしか記載されていませんが、
eeをceに変更するだけで良いようです - 今回はhttp://localhostに繋ぎに行くので最後のコマンドのようにlocalhostを指定するようです。
sudo apt-get update sudo apt-get install -y curl openssh-server ca-certificates tzdata perl sudo apt-get install -y postfix curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.deb.sh | sudo bash sudo EXTERNAL_URL="http://localhost" apt-get install gitlab-ce
GitLab CTL の使い方
何らかの問題があった際は以下のコマンドで設定ファイルの変更や起動をおこなってください。 なかなか遅いので要注意。
sudo gitlab-ctl stop # サービス停止 sudo gitlab-ctl reconfigure # 設定ファイル読み込み sudo gitlab-ctl start # サービス起動 sudo gitlab-ctl restart # サービス再起動
ブラウザで接続
http://localhost で入るとログイン画面が表示されるはずです。
初回ログイン
以下に初期パスワードが入っているので確認してください
sudo cat /etc/gitlab/initial_root_password
ユーザ名はrootで入れました。
最後に
お疲れ様でした。これで確認できるはずです。本来はEC2のUbuntuに載せたかったのですが、無料枠で使えるスペックがt2.microのみで仮想メモリ、スワップを追加してもうまくいきませんでした。なにかご存知の方法があれば教えてください。
【競プロ】巡回セールスマン問題【アルゴ式】
この記事でわかること
- 巡回セールスマン問題の解き方、考え方
- 最初に作ったコード
- あまりに無駄が多いのでリファクタする
- 最終的なコード
アルゴ式:貪欲法:循環セールスマン問題
アルゴ式を初めて見て、この問題に出会いました。
問題文
- 二次元座標上に N 個の頂点 0,1,…, N−1があり、頂点 i の座標は (X i , Y i) です。
- 頂点 0 からスタートしてすべての頂点を経由して頂点 0 に戻ります。総移動距離をできるだけ短くしてください。
ただし、ここでの距離はユークリッド距離 (日常生活で使われている距離) を指します。- これに対し、アルルは次のアルゴリズムを考えました。
- まだ訪れていない頂点がある場合は、今いる頂点からまだ訪れていない頂点のうち最も近い頂点に移動する。 ただし、距離が等しい頂点がある場合は最も番号が小さい頂点に移動する。全ての頂点を訪れた後は、頂点 0 に戻る。
- アルルの考えたアルゴリズムを実現するプログラムを作成してください。
入力
N X_0 Y_0 ... X_N-1 Y_N-1
※細かい説明は今回は省きます
出力
答えを出力する。
設計
- 座標クラス
Pointx:floaty:float
- 巡回セールスマン問題を解くクラス
SalesMann, x, y:float入力をとりあえずもっておくnow:Point現在の座標unvisit:list[Point]まだ訪れていない座標のリスト(英単語としておかしい)distances:list[float]実際に移動した距離を保持しておくリストhas_unvisit(): まだ訪れていない点がないか?get_distance(point_a, point_b): 二点の距離を求めるget_min_distance(now): 現在点からまだ訪れていない点の中で最小の距離を求めるgreed(): 貪欲法でこの問題を解いて、移動距離リストを更新する
main関数- 入力を受け付けて、巡回セールスマン問題を解いて、最後移動距離の和を出力
src
import math class Point: def __init__(self, x, y) -> None: self.x = x self.y = y class SalesMan: def __init__(self, n, x, y) -> None: self.n = n self.points = [] for i in range(n): p = Point(x[i], y[i]) self.points.append(p) self.now = self.points[0] self.unvisit = self.points.copy() self.unvisit.remove(self.now) self.distances = [] def has_unvisit(self) -> bool: return len(self.unvisit) >= 1 def get_distance(self, point_a, point_b): return math.sqrt((point_a.x - point_b.x) ** 2 + (point_a.y - point_b.y) ** 2) def get_min_distance_and_point(self, now): min_distance = None min_point = None for point in self.unvisit: now_distance = self.get_distance(now, point) if min_distance == None or now_distance < min_distance: min_distance = now_distance min_point = point return min_distance, min_point def greed(self): # まだ訪れていない頂点があるか? while self.has_unvisit(): # 最も近い点を計算 distance, point = self.get_min_distance_and_point(self.now) # 記録 self.unvisit.remove(point) self.distances.append(distance) self.now = point else: # すべて訪れたら終了 distance = self.get_distance(self.now, self.points[0]) self.distances.append(distance) return self.distances if __name__ == '__main__': n = int(input()) x = [] y = [] for _ in range(n): x_n, y_n = map(int, input().split()) x.append(x_n) y.append(y_n) salesMan = SalesMan(n, x, y) salesMan.greed() ans = sum(salesMan.distances) print(ans)
無事AC...
リファクタを考える
- L#15
nは保持しなくてもよさそう
unvisitはunvisitedのほうが正しそうget_distance()よりはcalc_distance()のほうが正しそうgreed()は間違っていそう。greedy algorithmなのでgreedyのほうがよさそう- 他は何か思いつかないので何かあれば指摘ください
【Unreal Engine】初めてのUnreal Engineを触ってみる。
初回はインストールから起動、実行、プリセットを起動、デプロイまでをやる
- 公式サイトからEpic Game Launcher をインストールする
Epic Game Launcher から Unreal Engine タブをクリックして、ライブラリから最新の v 5.2.1 をインストールする。

これを起動する
- 今回はFPSを見てみる

これで作成する

これをパッケージ化する

- パッケージ化されたファイル群を確認すると、EXEの実行ファイルができているのでこれをクリックするとゲームが起動できる
次回は細かく設定を見ていく
【PyTorch】Windows11にPIP経由でPyTorchの環境構築する
Anacondaとpipと、複数方法のPythonインストールのせいでごちゃごちゃになってしまっていたのでクリーンインストールしました...
- インストーラー経由でインストールしたものは、プログラムからアンインストールしてください。
- その他のライブラリ等々は手動で削除してください。”Windows Python Clean Uninstall”などで検索すればこの手の記事は出てきます
環境構築
以下の環境を前提とします。他には何もいりません!
- Window 11
公式HP
今回の手順はほぼ公式HPままです。
今回は以下の環境を用意します
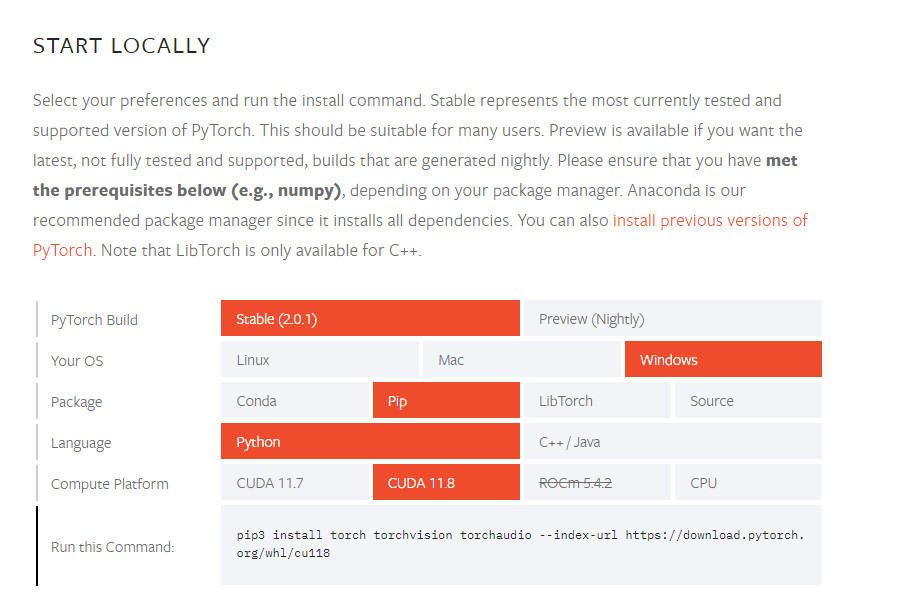
Install Python 3.11.4
PyTorchは3.8 - 3.11 をサポートしているようなので 3.11 をインストールします。
Python - Currently, PyTorch on Windows only supports Python 3.8-3.11; - Python 2.x is not supported.
Python Releases for Windows | Python.org
インストーラーを実行し、PATHを通すかどうかのチェックボックスがあるので有効にします。
PowerShellを起動し動作確認すると
PS C:\Users\username> python --version Python 3.11.4
pip のインストール
インストーラーを使った場合はすでにインストールされているので対応は不要です
PowerShellを起動し動作確認すると
PS C:\Users\usernamne> pip --version pip 23.1.2 from C:\Users\username\AppData\Local\Programs\Python\Python311\Lib\site-packages\pip (python 3.11)
Install CUDA 111.8
今回はCUDA 11.8 をインストールします。 過去のアーカイブスから該当のバージョンをダウンロードしてインストーラーを起動してください。
https://developer.nvidia.com/cuda-toolkit-archive
Install PyTorch via pip
最後にPyTorchをPIP経由でインストールします。 公式サイトの通りUIをぽちぽちしてでてきたコマンドをPowerShellに入力します。
PS > pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
これで環境構築は終了です。
Verification
適当なディレクトリでVSCODEなりエディターを開いて、「main.py」というファイルを作って以下のソースコードを書き込んでください。
import torch x = torch.rand(5, 3) print(x)
今回はVSCODEの右上の実行ボタンから実行してみます。(各種環境設定かもしれないです)
PS D:\dev\rinna> & C:/Users/UserName/AppData/Local/Programs/Python/Python311/python.exe d:/dev/rinna/main.py
tensor([[0.5635, 0.4686, 0.3982],
[0.8187, 0.0046, 0.9702],
[0.5056, 0.8050, 0.0878],
[0.5640, 0.1994, 0.8398],
[0.3953, 0.6621, 0.7090]])
無事動いてくれました!
本日はここまでにします。
【ChatGPT】ChatGPT APIとVoiceVoxとPythonでコンソール上でのチャットを読み上げてもらう
この記事でわかること
以前、selemiumを使ってWeb版のChatGPTの解答をスクレイピングして読み上げてもらうツールを作ったのですが、自動的に読み上げてもらうまで作れなかったので、こちらで実装しました。
目次
今回用意した環境
開発環境構築
以下の手順で行います。
- Voice Vox (Python Wheel版) のインストール
- ONNX Runtime のインストール
- Open JTalkのインストール
- PyAudioのインストール
- OpenAI (Pythonモジュール) のインストール
完成後のディレクトリはこのようになっている想定です
$ tree -L 1 . ├── README.md ├── main.py ├── onnxruntime-osx-x86_64-1.13.1 ├── onnxruntime-osx-x86_64-1.13.1.tgz ├── open_jtalk_dic_utf_8-1.11 └── open_jtalk_dic_utf_8-1.11.tar.gz 2 directories, 6 files
Voice Vox (Python Wheel版) のインストール
https://github.com/VOICEVOX/voicevox_core/releases
上のリンクから最新バージョンのものを利用したいと思います。(2023-07-07現在では0.14.4)
今回はMacOSで Python wheel を利用したいと思います。私はIntel Macを利用しているのでvoicevox_core-0.14.4+cpu-cp38-abi3-macosx_10_7_x86_64.whlを利用します。
以下のコマンドをターミナルに入力してインストールします。
pip3 install https://github.com/VOICEVOX/voicevox_core/releases/download/0.14.4/voicevox_core-0.14.4+cpu-cp38-abi3-macosx_10_7_x86_64.whl
ONNX Runtime のインストール
ONNX Runtime は、ONNX モデルを運用環境にデプロイするためのハイパフォーマンスの推論エンジンです。 クラウドとエッジの両方に最適化され、Linux、Windows、Mac で動作します。
VOICEVOXでも利用されているようです。
現状、VOICEVOXでは ONNX Runtime v1.13.1が利用されているのでこれを導入します。
https://github.com/microsoft/onnxruntime/releases/tag/v1.13.1
私はIntel Macを利用しているので、onnxruntime-osx-x86_64-1.13.1.tgzをダウンロードします。
tgzファイルを適当ディレクトリに入れて以下のコマンドで解凍します
tar -xvf ***.tgz
※この手順を飛ばすと出るエラー
この手順を飛ばすと以下のエラーが出るので注意。(検索に引っ掛かるようにあえて残しておきます。私は飛ばして失敗したので...)
library not loaded @rpath/libonnxruntime.1.13.1.dylib
Open JTalkのインストール
Open JTalkは日本語音声合成システムです。このソフトウェアは修正BSDライセンスの下でリリースされています。
https://sourceforge.net/projects/open-jtalk/
こちらからダウンロードしてください。
ダウンロードしたtgzファイルを適当ディレクトリに入れて以下のコマンドで解凍します
tar -xvf ***.tgz
この手順を飛ばすと出る可能性のあるエラー
playsound is relying on a python 2 subprocess. Please use `pip3 install PyObjC` if you want playsound to run more efficiently.
Traceback (most recent call last):
File "[path]/ChatgptToVoiceVox/main.py", line 28, in <module>
main()
File "[path]/ChatgptToVoiceVox/main.py", line 23, in main
audio_query: AudioQuery = core.audio_query(DEMO_TEXT, SPEAKER_ID)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
voicevox_core.VoicevoxError: OpenJTalkの辞書が読み込まれていません
PyAudioのインストール
- 今回はPyAudioを使いました。
- wavファイルを作成せず、メモリを利用して simpleaudio で 生成した音声データを再生するとノイズが除去できなかったためこちらを利用しています。
brew install PortAudio pip3 install pyaudi
openai (Pythonモジュール)をインストール
pip3 install openai
ChatGPT API キー取得
2023-07-07現在では5$まで無料のようです。tokenをある程度つかっても限界にはならなさそうで、クレカ登録も不要だったので、利用します。
基本的には他のサイトでも紹介されているとおりの方法で取得できます。
4. Python 実装
まずは作成したソースコードをそのまま貼り付けます。のちほど解説していきます。
あと正直いらいないものも含まれているのですみません...
#!/usr/bin/env python3 # -*- coding: utf-8 -*- from __future__ import annotations import io import os import wave import re from time import sleep import asyncio from ctypes import CDLL from pathlib import Path # ONNX Runtime のダイナミックライブラリをimport CDLL(str(Path('onnxruntime-osx-x86_64-1.13.1/lib/libonnxruntime.dylib').resolve(strict=True))) # OPEN JTalk のパス open_jtalk_path=Path('open_jtalk_dic_utf_8-1.11') from voicevox_core import AudioQuery, VoicevoxCore import pyaudio import openai SPEAKER_ID = 29 DEMO_TEXT = "こんにちは。こちらはテスト音声です。" DEMO_LONG_TEXT = '''はい、自己紹介させていただきます。 初めまして、私はAIのアシスタントです。私の名前はOpenAI GPT-3です。私は自然言語処理を用いて、様々な質問や会話に対応することができます。 私は多くの分野について知識を持っており、文法や表現にも精通しています。また、日本語だけでなく、英語や他の言語にも対応することができます。 私の目的は、ユーザーのお手伝いをすることです。質問や疑問があれば、どんなことでもお気軽にお聞きください。私は最善の答えを提供するために努力します。 どうぞよろしくお願いします。 ''' FAIL_TEXT = "チャットGPTでのテキスト生成に失敗しました。しばらく待ってから試してみてください。" MODEL = "gpt-3.5-turbo" openai.api_key = "" # [MUST] please input your api_key def generate_text(prompt, conversation_history): try: conversation_history.append({"role": "user", "content": prompt}) response = openai.ChatCompletion.create( model=MODEL, messages=conversation_history, temperature=0.2, # 創造性の指標 max_tokens=2048, ) content = response.choices[0].message["content"] # print(content) # 会話履歴を追加 conversation_history.append({"role": "assistant", "content": content}) return content except Exception as e: print(e) return FAIL_TEXT def play_wavfile(wav_file: bytes): # Defines a chunk size chunk = 1024 p = pyaudio.PyAudio() # Bytes型の音声データをWave_read型に変換する wr: wave.Wave_read = wave.open(io.BytesIO(wav_file)) # wavファイルを書き込むストリームを作成する。 # 出力を "True "に設定すると、サウンドは録音されるのではなく、"再生 "される。 stream = p.open( format=p.get_format_from_width(wr.getsampwidth()), channels=wr.getnchannels(), rate=wr.getframerate(), output=True ) # Read data in chunks data = wr.readframes(chunk) # Play the sound by writing the audio data to the stream while data : stream.write(data) data = wr.readframes(chunk) sleep(0.01) stream.stop_stream() stream.close() p.terminate() def speakToChat(answer: str = None) -> None: core: VoicevoxCore = VoicevoxCore(open_jtalk_dict_dir=open_jtalk_path) core.load_model(SPEAKER_ID) if not answer == None: sentence_list = re.split("。", answer) else: sentence_list = [FAIL_TEXT] for sentence in sentence_list: sentence_sub = sentence.strip() output = 'No.7: ' + sentence_sub output = output if output[-1] == '?' else output + '。' print(output) wave_bytes: bytes = core.tts(sentence_sub, SPEAKER_ID) play_wavfile(wav_file=wave_bytes) def directSpeakToChat(book: str = None): core: VoicevoxCore = VoicevoxCore(open_jtalk_dict_dir=open_jtalk_path) core.load_model(SPEAKER_ID) if not book == None: wave_bytes: bytes = core.tts(book, SPEAKER_ID) play_wavfile(wav_file=wave_bytes) else: sentence_list = [FAIL_TEXT] if __name__ == '__main__': # 会話履歴を格納するためのリストを初期化 conversation_history = [] while True: # ユーザーに質問を入力させる input_prompt = input("prompt: ") generated_text = generate_text(input_prompt, conversation_history) speakToChat(answer=generated_text)
実行結果
$ p main2.py prompt: 何か褒めてください! No.7: あなたはとても親切で思いやりのある人です。 No.7: 周りの人々をいつも助けていて、その優しさは本当に素晴らしいです。 No.7: また、あなたの明るい笑顔は周りの人々に元気を与えています。 No.7: あなたのポジティブなエネルギーはとても魅力的で、人々を引き付ける力があります。 No.7: あなたの努力と頑張りは誰もが認めるべきです。 No.7: 素晴らしい人間性を持っているあなたは、周りの人々にとって本当に大切な存在です。
やり残したこと
- 実装の説明が足りていないです。
- 文章のセパレータが「。」になっているが「!」「?」は大丈夫なのか?
- 音声生成と音声読み上げをマルチスレッドにしたら高速化できそうだがスレッドセーフな実装をするのはコストかかりそう?
- コンソール上でのチャットだがWebGLなどに組み込めないか?そしたらLive2Dが喋っているように見えそう?